集群入门
Figure 1. A cluster with one empty node

NODE代表每个集群实例中的一个节点,cluster是由一组包含相同的cluster.name的节点构成。每当节点新加入或剔除时,集群会自动均分数据到各个节点上。
集群中一个节点会被选举成为master节点,负责管理集群范围内的修改,如添加删除索引,增删节点等。master节点不需要涉及文档级别的修改或搜索,这意味着只有一个master节点不会成为传输瓶颈。这个架构范例中只有一个节点,因此扮演者master角色。
用户可以和集群中任何节点通信,包括master,每个节点都知道需要的文档在哪,并且可以重定向访问到存储所需数据的节点上。
集群健康度
集群健康度status会返回green, yellow, or red:
GET /_cluster/health
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 0,
"active_shards": 0,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0
}
status返回的三种颜色说明:
green: All primary and replica shards are active.yello: All primary shards are active, but not all replica shards are active.red: Not all primary shards are active.
创建索引
在添加数据到集群之前,我们需要创建索引。索引是一个指向一个或多个物理shard的逻辑命名空间。
shard存储着所有index的一个小分片。ES通过shard的形式分布式存储数据。一个Shard可以有primary和replica属性。其中,索引中的每个文档都会属于一个primary shard,所以primary shard的数量决定了最多能寸多少文档。replica是一份primary的拷贝,用于冗余存储以及查询数据。
理论上一个primary shard可以存储的文档数上限为
Integer.MAX_VALUE - 128。但实际中会受限于硬件条件。
primary shard的数量在索引创建时就固定好了,但是replica shard的数量可以随时动态修改。
默认情况下,一个索引会分配5个primary shards。下述范例中创建blogs这个index,修改了primary shards数量:
PUT /blogs
{
"settings" : {
"number_of_shards" : 3,
"number_of_replicas" : 1
}
}
Figure 2. A single-node cluster with an index

此时检测cluster-health,可以看到以下输出:
{
"cluster_name": "elasticsearch",
"status": "yellow",
"timed_out": false,
"number_of_nodes": 1,
"number_of_data_nodes": 1,
"active_primary_shards": 3,
"active_shards": 3,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 3,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 50
}
status变成了yellow。同时,unassigned_shards有3个。
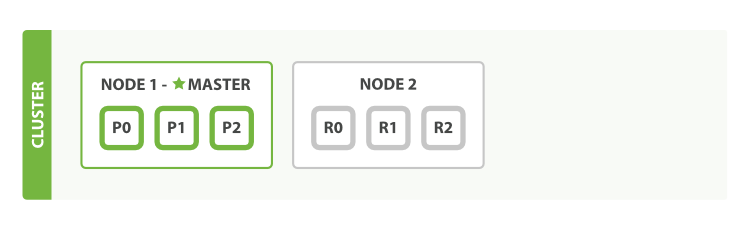
故障迁移
单节点会出现单点失败的故障,加入第二个节点即可避免单点故障。
Figure 3. A two-node cluster—all primary and replica shards are allocated
第二个节点加入后,3个未分配的replica shards就会分配给这个节点。
新索引的数据会首先存储在一个primary shard,然后拷贝到replica shard。
{
"cluster_name": "elasticsearch",
"status": "green",
"timed_out": false,
"number_of_nodes": 2,
"number_of_data_nodes": 2,
"active_primary_shards": 3,
"active_shards": 6,
"relocating_shards": 0,
"initializing_shards": 0,
"unassigned_shards": 0,
"delayed_unassigned_shards": 0,
"number_of_pending_tasks": 0,
"number_of_in_flight_fetch": 0,
"task_max_waiting_in_queue_millis": 0,
"active_shards_percent_as_number": 100
}
此时状态就是green。
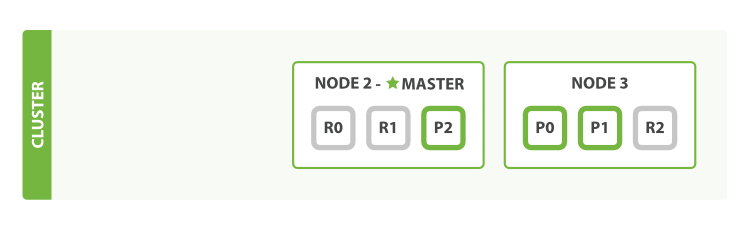
水平扩展
只是添加集群节点即可。
Figure 4. A three-node cluster—shards have been reallocated to spread the load
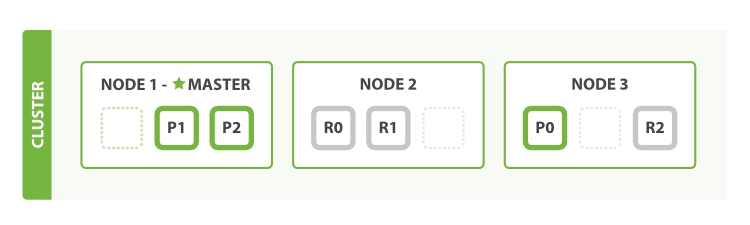
PUT /blogs/_settings
{
"number_of_replicas" : 2
}
Figure 5. Increasing the number_of_replicas to 2
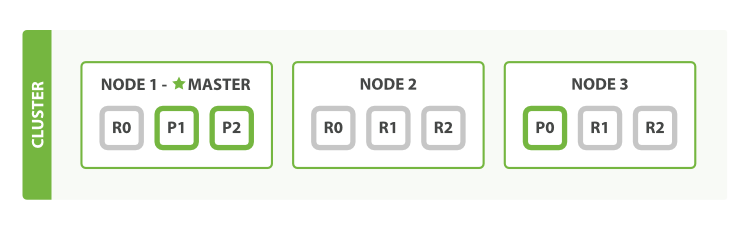
故障迁移