聚合测试
我们可以用以下几页定义不同的聚合和它们的语法,但学习聚合的最佳途径就是用实例来说明。一旦我们获得了聚合的思想,以及如何合理地嵌套使用它们,那么语法就变得不那么重要。
Note: 聚合桶和指标的完整列表可以在参考Elasticsearch Reference。很多我们将会在这章讲到,但是你可以浏览所有你熟悉的功能。
现在我们以一个例子来深入研究一下,我们建立一些聚合,也许它对汽车经销商有用。我们的数据是关于汽车交易的:车型,制造商,销售价等等…… 首先,我们先索引一些数据:
POST /cars/transactions/_bulk
{ "index": {}}
{ "price" : 10000, "color" : "red", "make" : "honda", "sold" : "2014-10-28" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 30000, "color" : "green", "make" : "ford", "sold" : "2014-05-18" }
{ "index": {}}
{ "price" : 15000, "color" : "blue", "make" : "toyota", "sold" : "2014-07-02" }
{ "index": {}}
{ "price" : 12000, "color" : "green", "make" : "toyota", "sold" : "2014-08-19" }
{ "index": {}}
{ "price" : 20000, "color" : "red", "make" : "honda", "sold" : "2014-11-05" }
{ "index": {}}
{ "price" : 80000, "color" : "red", "make" : "bmw", "sold" : "2014-01-01" }
{ "index": {}}
{ "price" : 25000, "color" : "blue", "make" : "ford", "sold" : "2014-02-12" }
现在我们有了一些数据,让我们先构建第一个聚合。汽车经销商也许想知道哪种颜色的车卖的最好。其实这是一个通过一个简单聚合很容易完成的任务。我们将用terms桶来做这个事:
GET /cars/transactions/_search
{
"size" : 0,
"aggs" : {
"popular_colors" : {
"terms" : {
"field" : "color"
}
}
}
}
- 聚合放在最顶层
aggs参数。 - 然后我们给聚合取个名字,表达我们想做什么,在这个例子中为
popular_colors。 - 最后,我们定义一个terms类型的桶。
聚合是在上下文查询时被执行,这意味着他在查询请求时只是另外一个顶层参数(例如:使用/_search endpoint)。聚合何以搭配查询,我们将在Scoping Aggregations介绍。
Note: 你会注意到
size被设置为零。因为我们不关心这个搜索的结果,并且这样可以加速搜索。设置size为0等价于在ES 1.x中使用count聚合类型。
下一步,我们为我们的聚合命名。取什么名字由你决定;这样响应将会被打上标签,之后你的应用程序可以根据你提供的名字解析这个结果。
接下来,我们定义聚合本身。在这个例子中,我们定义一个terms桶。terms桶将动态地为每个唯一的term创建一个新的桶。因为我们告诉它使用color字段,所以terms桶将动态地为每一种color创建一个新的桶。
让我们来执行一下这个聚合,看一下输出结果:
{
...
"hits": {
"hits": []
},
"aggregations": {
"colors": {
"buckets": [
{
"key": "red",
"doc_count": 4
},
{
"key": "blue",
"doc_count": 2
},
{
"key": "green",
"doc_count": 2
}
]
}
}
}
- 没有搜索到的结果返回,因为我们设置了
size参数。 - 我们的
colors聚合返回作为aggregations部分的字段。 - 每一个
key和在color字段中唯一term是一致的。一般总是包含doc_count值,它告诉我们有多少文档包含这个term。 - 每个桶的计数代表这种
color的文档数量。
这个响应包含了一个buckets的列表,每个对应一个唯一的颜色(例如,红色或绿色)。每个桶还包括文档的数量的一个计数,“嵌入”在特定的桶里。例如,有四个红色的汽车。
前面的示例完全是实时的:如果文档可搜索,他们将可以被聚合。这意味着你可以直接聚合结果,管道输到一个图形库中生成实时的仪表板。只要你卖一辆银色汽车,你的图会动态更新包括银汽车统计信息
添加一个指标(Adding a Metric to the Mix)
前面的例子告诉每个桶中文档的数量,它是有用的。但通常,我们的应用程序需要关于这些文档更复杂的指标。例如,在每个桶中的车的平均价格是多少?
为了得到这些信息,我们需要告诉Elasticsearch在哪些字段上去计算哪个指标。这需要桶内嵌套指标。然后ES会基于桶里的文档内容做一些数理统计,最终计算出指标量。
现在为汽车示例加一个平均值指标:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
}
}
}
}
}
- 我们添加了一个
aggs级别的指标。 - 给这个指标取名为
avg_price。 - 最后,我们定义它作为
price字段avg指标。
响应结果可以看到,我们想要的指标量已经计算出来了:
{
...
"aggregations": {
"colors": {
"buckets": [
{
"key": "red",
"doc_count": 4,
"avg_price": {
"value": 32500
}
},
{
"key": "blue",
"doc_count": 2,
"avg_price": {
"value": 20000
}
},
{
"key": "green",
"doc_count": 2,
"avg_price": {
"value": 21000
}
}
]
}
}
...
}
虽然响应的只有很小的变化,但我们得到的了更有价值的数据。之前,我们知道有四个红色的汽车。现在我们知道红色汽车的平均价格是32500美元。这些可以直接插入报告或图表中使用。
Buckets Inside Buckets
聚合的威力很大,在上一个例子中我们只是在桶中嵌套指标量,已经效果很明显了。但是更让人兴奋的是可以在桶中在嵌套桶。这一次,我们想搜索每种颜色的车的制造商的分布:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": {
"avg": {
"field": "price"
}
},
"make": {
"terms": {
"field": "make"
}
}
}
}
}
}
让我们看看响应结果(为简便起见省略了一些内容):
{
...
"aggregations": {
"colors": {
"buckets": [
{
"key": "red",
"doc_count": 4,
"make": {
"buckets": [
{
"key": "honda",
"doc_count": 3
},
{
"key": "bmw",
"doc_count": 1
}
]
},
"avg_price": {
"value": 32500
}
},
...
}
响应结果告诉我们:
- 有4辆红色车
- 红色车的平均价是 $32,500
- 3辆红色车是Honda制造的,1辆是BMW
One Final Modification
让我们再添加两个指标量来计算每个制造商每种颜色的车的最高价和最低价:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"colors": {
"terms": {
"field": "color"
},
"aggs": {
"avg_price": { "avg": { "field": "price" }
},
"make" : {
"terms" : {
"field" : "make"
},
"aggs" : {
"min_price" : { "min": { "field": "price"} },
"max_price" : { "max": { "field": "price"} }
}
}
}
}
}
}
这就是输出的结果:
{
...
"aggregations": {
"colors": {
"buckets": [
{
"key": "red",
"doc_count": 4,
"make": {
"buckets": [
{
"key": "honda",
"doc_count": 3,
"min_price": {
"value": 10000
},
"max_price": {
"value": 20000
}
},
{
"key": "bmw",
"doc_count": 1,
"min_price": {
"value": 80000
},
"max_price": {
"value": 80000
}
}
]
},
"avg_price": {
"value": 32500
}
},
...
min 和 max 度量现在出现在每个汽车制造商下面。
有了这两个桶,我们可以对查询的结果进行扩展并得到以下信息:
- 有四辆红色车。
- 红色车的平均售价是 $32,500 美元。
- 其中三辆红色车是 Honda 本田制造,一辆是 BMW 宝马制造。
- 最便宜的红色本田售价为 $10,000 美元。
- 最贵的红色本田售价为 $20,000 美元。
生成柱状图
聚合还有一个令人激动的特性就是能够十分容易地将它们转换成图表和图形。本章中,我们会关注于各种各样的分析并反复“蹂躏”我们示例中的数据。我们也会展现聚合可以支持的不同种类的图表。
直方图(histogram)桶特别有用,它本质上是一个条形图,如果有创建报表或分析仪表盘的经验,那么我们会毫无疑问的发现里面有一些图表是条形图。直方图是根据指定的间隔显示的,如果需要售价的直方图,我们可能指定的间隔值为 20,000。它会每 $20,000 创建新桶。然后文档会被分到对应的桶中。
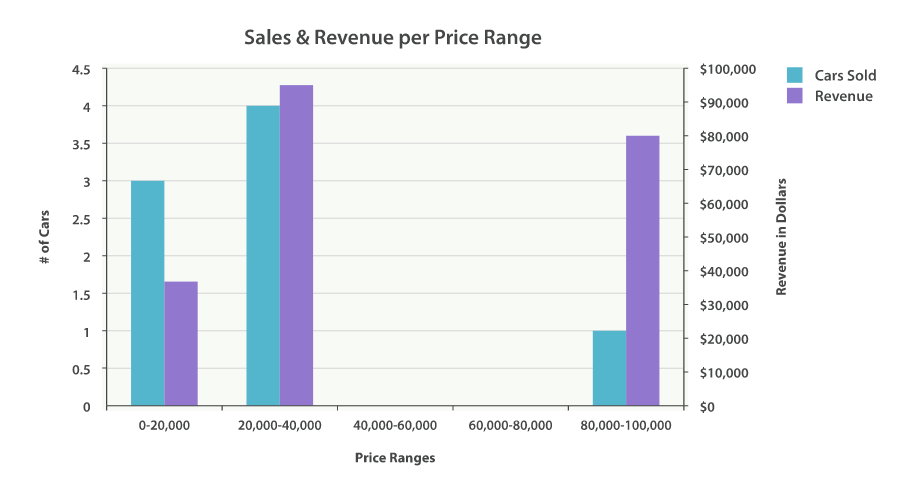
对于仪表盘来说,我们希望知道每个售价区间内汽车的销量。我们还会想知道每个售价区间内汽车所带来的收入,可以通过对每个区间内已售汽车的售价求和得到。
可以用 histogram 和一个嵌套的 sum 度量得到我们想要的答案:
GET /cars/transactions/_search
{
"size" : 0,
"aggs":{
"price":{
"histogram":{
"field": "price",
"interval": 20000
},
"aggs":{
"revenue": {
"sum": {
"field" : "price"
}
}
}
}
}
}
- histogram 桶要求两个参数:一个数值字段以及一个定义桶大小间隔字段。
- sum 度量嵌套在每个售价区间内,用来显示每个区间内的总收入。
如我们所见,查询是围绕 price 聚合构建的,它包含一个 histogram 桶。这个桶要求一个供计算的数值字段,以及一个间隔大小。这个间隔值定义了桶的“宽度”。20000 这个宽度表示我们得到的返回是 [0-19999, 20000-39999, ...] 。
接着,我们在直方图内定义嵌套的度量,这个 sum 度量会将售价范围内每个文档的售价字段里的值加起来。这可以为我们提供每个售价区间的收入,从而可以发现到底是普通家用车赚钱还是奢侈车赚钱。
响应结果如下:
{
...
"aggregations": {
"price": {
"buckets": [
{
"key": 0,
"doc_count": 3,
"revenue": {
"value": 37000
}
},
{
"key": 20000,
"doc_count": 4,
"revenue": {
"value": 95000
}
},
{
"key": 80000,
"doc_count": 1,
"revenue": {
"value": 80000
}
}
]
}
}
}
结果很容易理解,不过应该注意到直方图的键值是区间的下限。键 0 代表区间 0-19,999,键 20000 代表区间 20,000-39,999 等等。
NOTE: 我们可能会注意到空的区间,比如:$40,000-60,000,没有出现在响应中。histogram 桶默认会忽略它,因为它有可能会导致不希望的潜在错误输出。 我们会在下一小节中讨论如何包括空桶。返回空桶(Returning Empty Buckets)
Figure 35. Sales and Revenue per price bracket
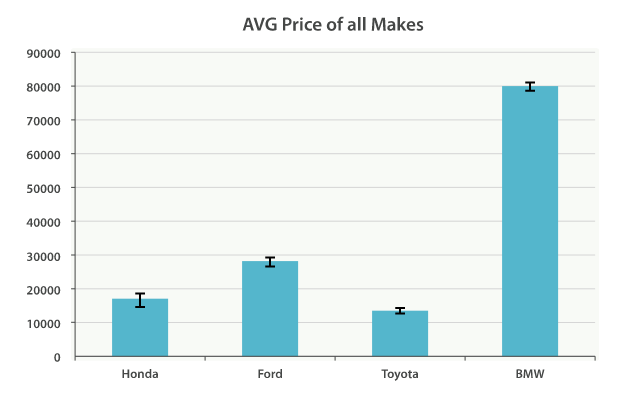
当然,我们可以为任何聚合输出的分类和统计结果创建条形图,而不只是直方图桶。让我们以最受欢迎 10 种汽车以及它们的平均售价、标准差这些信息创建一个条形图。我们会用到 terms 桶和 extended_stats 度量:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"makes": {
"terms": {
"field": "make",
"size": 10
},
"aggs": {
"stats": {
"extended_stats": {
"field": "price"
}
}
}
}
}
}
它会按照欢迎度返回制造商列表以及它们各自的统计信息。我们会对 stats.avg、stats.count 和 stats.std_deviation 信息特别感兴趣,并用它们计算出标准误差:
std_err = std_deviation / count
创建图表如图 Figure 36, “Average price of all makes, with error bars”.