时间数据处理(Looking at Time)
如果在ES中,搜索是最常见的行为,那么创建日期柱状图(Date Histogram)肯定是第二常见的。为什么要使用日期柱状图呢?
- 想象在你的数据中有一个时间戳。数据是什么不重要-Apache日志事件,股票交易日期,棒球比赛时间-任何拥有时间戳的数据都能通过日期柱状图受益。当你有时间戳时,你经常会想创建基于时间的指标信息:
- 今年的每个月销售了多少辆车?
- 过去的12小时中,这只股票的价格是多少?
- 上周每个小时我们的网站的平均延迟是多少?
常规的histogram通常使用条形图来表示,而date histogram倾向于被装换为线图(Line Graph)来表达时间序列(Time Series)。很多公司使用ES就是为了对时间序列数据进行分析。
date_histogram的工作方式和常规的histogram类似。常规的histogram是基于数值字段来创建数值区间的桶,而date_histogram则是基于时间区间来创建桶。因此每个桶是按照某个特定的日历时间定义的(比如,1个月或者是2.5天)。
常规Histogram能够和日期一起使用吗?
从技术上而言,是可以的。常规的histogram桶可以和日期一起使用。但是,它并不懂日期相关的信息(Not calendar-aware)。而对于date_histogram,你可以将间隔(Interval)指定为1个月,它知道2月份比12月份要短。date_histogram还能够和时区一同工作,因此你可以根据用户的时区来对图形进行定制,而不是根据服务器。
常规的histogram会将日期理解为数值,这意味着你必须将间隔以毫秒的形式指定。同时聚合也不理解日历间隔,所以它对于日期几乎是没法使用的。
第一个例子中,我们会创建一个简单的线图(Line Chart)来回答这个问题:每个月销售了多少辆车?
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "month",
"format": "yyyy-MM-dd"
}
}
}
}
在查询中有一个聚合,它为每个月创建了一个桶。它能够告诉我们每个月销售了多少辆车。同时指定了一个额外的格式参数让桶拥有更"美观"的键值。在内部,日期被简单地表示成数值。然而这会让UI设计师生气,因此使用格式参数可以让日期以更常见的格式进行表示。
得到的响应符合预期,但是也有一点意外(看看你能够察觉到):
{
...
"aggregations": {
"sales": {
"buckets": [
{
"key_as_string": "2014-01-01",
"key": 1388534400000,
"doc_count": 1
},
{
"key_as_string": "2014-02-01",
"key": 1391212800000,
"doc_count": 1
},
{
"key_as_string": "2014-05-01",
"key": 1398902400000,
"doc_count": 1
},
{
"key_as_string": "2014-07-01",
"key": 1404172800000,
"doc_count": 1
},
{
"key_as_string": "2014-08-01",
"key": 1406851200000,
"doc_count": 1
},
{
"key_as_string": "2014-10-01",
"key": 1412121600000,
"doc_count": 1
},
{
"key_as_string": "2014-11-01",
"key": 1414800000000,
"doc_count": 2
}
]
...
}
聚合完整地被表达出来了。你能看到其中有用来表示月份的桶,每个桶中的文档数量,以及漂亮的key_as_string。
返回空桶
发现在上面的响应中的奇怪之处了吗?
是的,我们缺失了几个月!默认情况下,date_histogram(以及histogram)只会返回文档数量大于0的桶。
这意味着得到的histogram响应是最小的。但是有些时候该行为并不是我们想要的。对于很多应用而言,你需要将得到的响应直接置入到一个图形库中,而不需要任何额外的处理。
因此本质上,我们需要返回所有的桶,哪怕其中不含有任何文档。我们可以设置两个额外的参数来实现这一行为:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "month",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
}
}
}
}
- 以上的
min_doc_count参数会强制返回空桶, extended_bounds参数会强制返回一整年的数据。
这两个参数会强制返回该年中的所有月份,无论它们的文档数量是多少。min_doc_count的意思很容易懂:它强制返回哪怕为空的桶。
extended_bounds参数需要一些解释。min_doc_count会强制返回空桶,但是默认ES只会返回在你的数据中的最小值和最大值之间的桶。
因此如果你的数据分布在四月到七月,你得到的桶只会表示四月到七月中的几个月(可能为空,如果使用了min_doc_count=0)。为了得到一整年的桶,我们需要告诉ES需要得到的桶的范围。
extended_bounds参数就是用来告诉ES这一范围的。一旦你添加了这两个设置,得到的响应就很容易被图形生成库处理而最终得到下图:
Figure 37. Cars sold over time
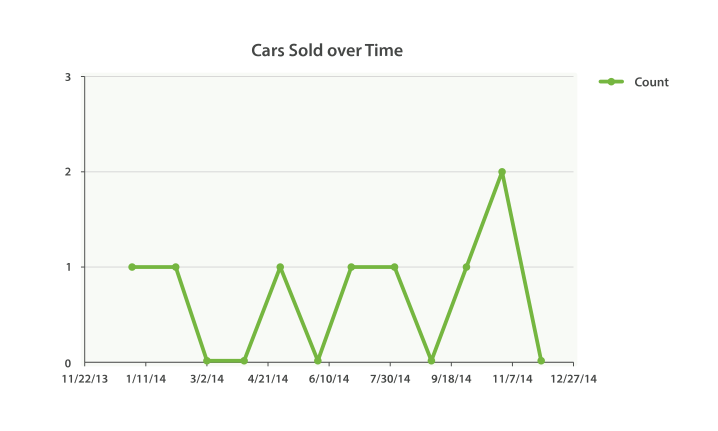
扩展案例
我们已经看到过很多次,为了实现更复杂的行为,桶可以嵌套在桶中。为了说明这一点,我们会创建一个用来显示每个季度,所有制造商的总销售额的聚合。同时,我们也会在每个季度为每个制造商单独计算其总销售额,因此我们能够知道哪种汽车创造的收益最多:
GET /cars/transactions/_search
{
"size" : 0,
"aggs": {
"sales": {
"date_histogram": {
"field": "sold",
"interval": "quarter",
"format": "yyyy-MM-dd",
"min_doc_count" : 0,
"extended_bounds" : {
"min" : "2014-01-01",
"max" : "2014-12-31"
}
},
"aggs": {
"per_make_sum": {
"terms": {
"field": "make"
},
"aggs": {
"sum_price": {
"sum": { "field": "price" }
}
}
},
"total_sum": {
"sum": { "field": "price" }
}
}
}
}
}
可以发现,interval参数被设成了quarter。
得到的响应如下(删除了很多):
{
....
"aggregations": {
"sales": {
"buckets": [
{
"key_as_string": "2014-01-01",
"key": 1388534400000,
"doc_count": 2,
"total_sum": {
"value": 105000
},
"per_make_sum": {
"buckets": [
{
"key": "bmw",
"doc_count": 1,
"sum_price": {
"value": 80000
}
},
{
"key": "ford",
"doc_count": 1,
"sum_price": {
"value": 25000
}
}
]
}
},
...
}
我们可以将该响应放入到一个图形中,使用一个线图(Line Chart)来表达总销售额,一个条形图来显示每个制造商的销售额(每个季度),如下所示:
Figure 38. Sales per quarter, with distribution per make
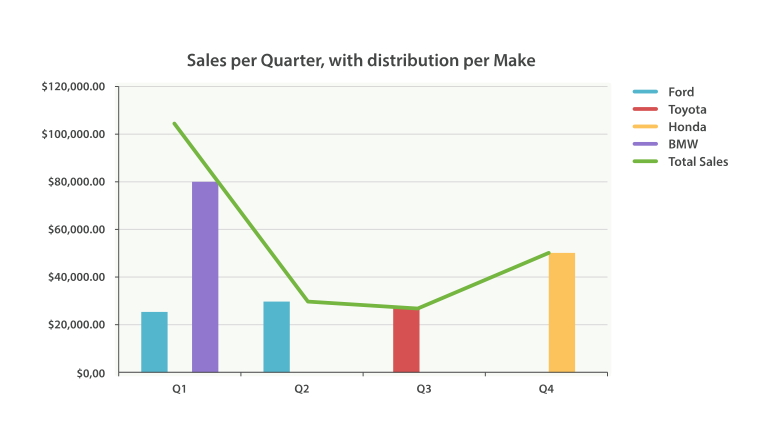
无限的可能性(The Sky’s the Limit)
显然它们都是简单的例子,但是在对聚合进行绘图时,是存在无限的可能性的。比如,下图是Kibana中的一个用来进行实时分析的仪表板,它使用了很多聚合:
Figure 39. Kibana—a real time analytics dashboard built with aggregations
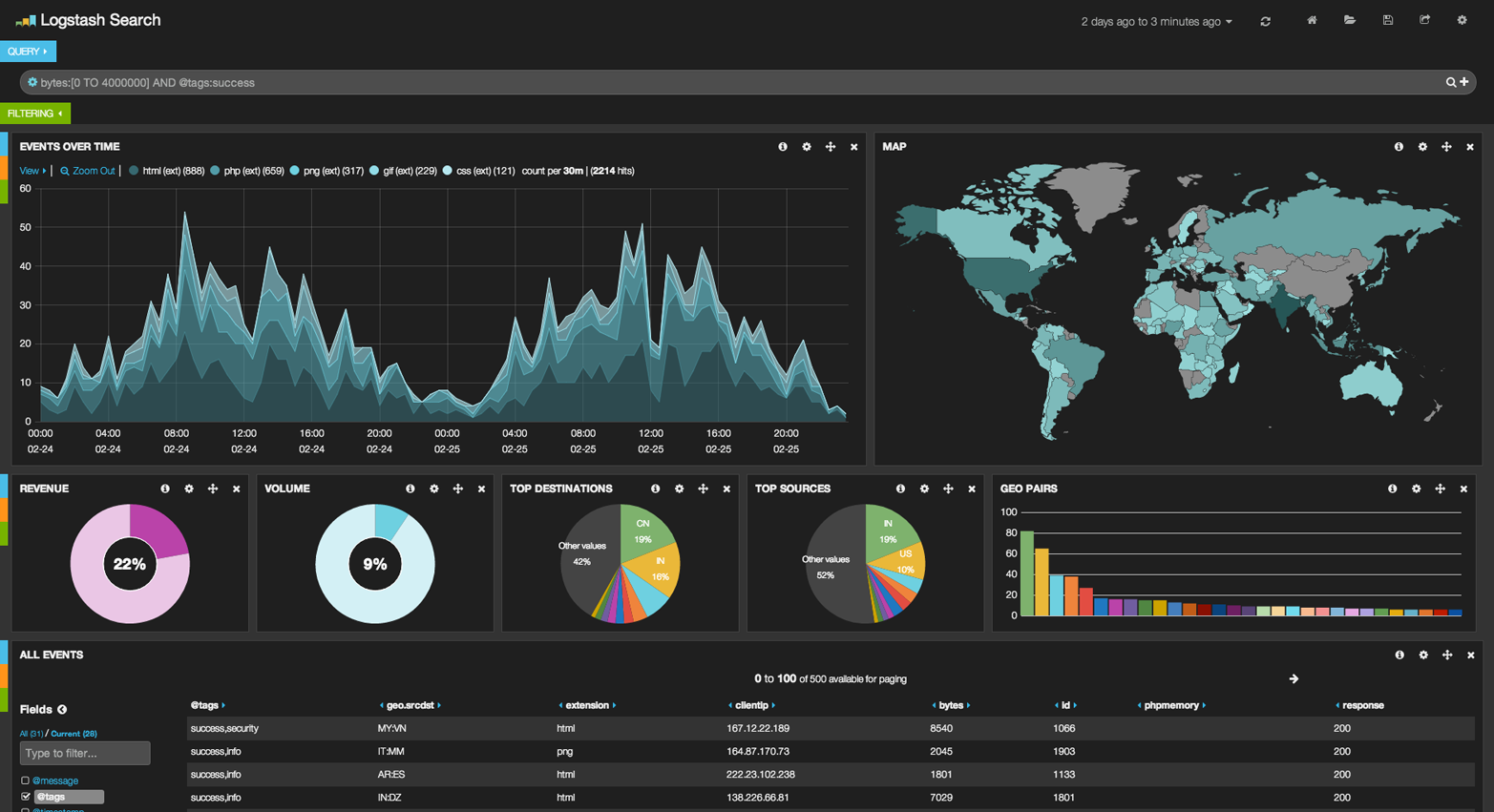 因为聚合的实时性,类似这样的仪表板是很容易进行查询,操作和交互的。这让它们非常适合非技术人员和分析人员对数据进行分析,而不需要他们创建一个Hadoop任务。
因为聚合的实时性,类似这样的仪表板是很容易进行查询,操作和交互的。这让它们非常适合非技术人员和分析人员对数据进行分析,而不需要他们创建一个Hadoop任务。
为了创建类似Kibana的强大仪表板,你需要掌握一些高级概念,比如作用域(Scoping),过滤(Filtering)和聚合排序(Sorting Aggregations)。
聚合作用域(Scoping Aggregations)
到现在给出的聚合例子中,你可能已经发现了在搜索请求中我们省略了query子句。整个请求只是一个简单的聚合。
聚合可以和搜索请求一起运行,但是你需要理解一个新概念:作用域(Scope)。默认情况下,聚合和查询使用相同的作用域。换句话说,聚合作于匹配了查询的文档集。
让我们看看之前的一个聚合例子:
GET /cars/transactions/_search?search_type=count
{
"aggs" : {
"colors" : {
"terms" : {
"field" : "color"
}
}
}
}
你可以发现聚合是孤立存在的。实际上,在ES中"不指定查询"和"查询所有文档"是等价的。前述查询在内部会被转换如下:
GET /cars/transactions/_search?search_type=count
{
"query" : {
"match_all" : {}
},
"aggs" : {
"colors" : {
"terms" : {
"field" : "color"
}
}
}
}
聚合总是在查询的作用域下工作的,因此一个孤立的聚合实际上工作在match_all查询的作用域 - 即所有文档。
一旦了解了这一点,我们就可以开始对聚合进行定制了。前面的所有例子都计算了关于所有数据的统计信息:最热卖的车,所有车的平均价格,每个月的最大销售额等等。
有了作用域,我们可以问这种问题”Ford汽车有几种可选的颜色?“,通过向请求中添加一个查询来完成(使用match查询):
GET /cars/transactions/_search
{
"query" : {
"match" : {
"make" : "ford"
}
},
"aggs" : {
"colors" : {
"terms" : {
"field" : "color"
}
}
}
}
通过省略search_type=count,我们可以得到搜索结果以及聚合结果如下:
{
...
"hits": {
"total": 2,
"max_score": 1.6931472,
"hits": [
{
"_source": {
"price": 25000,
"color": "blue",
"make": "ford",
"sold": "2014-02-12"
}
},
{
"_source": {
"price": 30000,
"color": "green",
"make": "ford",
"sold": "2014-05-18"
}
}
]
},
"aggregations": {
"colors": {
"buckets": [
{
"key": "blue",
"doc_count": 1
},
{
"key": "green",
"doc_count": 1
}
]
}
}
}
这看起来没什么,但是它是生成更加强大的高级仪表板的关键。你可以通过添加一个搜索栏将任何静态的仪表板转换成一个实时数据浏览工具。这让用户能够搜索词条然后看到所有实时图表(它们由聚合提供支持,使用查询的作用域)。用Hadoop来实现试试看!
全局桶(Global Bucket)
你经常需要你的聚合和查询拥有相同的作用域。但是有时你也需要搜索数据的一个子集,而在所有数据上进行聚合。
比如,你想要知道Ford车相较所有车的平均价格。我们可以使用一个通常的聚合(作用域和查询相同)来得到Ford车的平均价格。而所有车的平均价格则可以通过全局桶来得到。
全局桶会包含你的所有文档,无论查询作用域是什么; 它完全绕开了作用域。由于它是一个桶,你仍然可以在其中嵌入聚合:
GET /cars/transactions/_search?search_type=count
{
"query" : {
"match" : {
"make" : "ford"
}
},
"aggs" : {
"single_avg_price": {
"avg" : { "field" : "price" }
},
"all": {
"global" : {},
"aggs" : {
"avg_price": {
"avg" : { "field" : "price" }
}
}
}
}
}
该聚合作用在查询作用域中(比如,所有匹配了ford的文档); 全局桶没有任何参数; 聚合在所有文档上操作,无论制造商是哪一个。
single_avg_price指标基于查询作用域(即所有ford车)完成计算。avg_price是一个嵌套在全局桶中的指标,意味着他会忽略作用与的概念,而针对所有文档完成计算。该聚合得到的平均值代表了所有车的平均价格。
如果你已经读到了本书的这个地方,你会认识到这一真言:在任何可以使用过滤器(Filter)的地方使用它。这一点对于聚合同样适用,在下一章中我们会介绍如果对聚合进行过滤,而不是仅仅对查询作用域作出限制。